The Scrolling Problem
We’re training and conditioning a whole new generation of people that when we are uncomfortable or lonely or uncertain or afraid we have a digital pacifier for ourselves that is kind of atrophying our own ability to deal with that.”
— Tristan Harris, former design ethicist at Google and co-founder of Centre for Humane Technologies. From The Social Dilemma
Introduction
We make the assumption every day that we have to scroll through our feeds. When we do a Google search, or a PubMed search if you're a biomedical researcher like me, we assume that the relevant results will be at the very top of the list. This might work for specific searches, but not broader ones. We run into big issues when we're checking the news or social media, where we face an infinite, constantly updating feed that serves us. We find ourselves mindlessly scrolling through a one-dimensional list, with little if any control over what hypernormal, outrage-inducing content the AI algorithms controlling the feed will serve up next. This includes "recommended" content and tailored ads, an additional layer that takes away even more control over what we see. We do this because there is no alternative.
I define the set of negative issues caused by the act of scrolling, and especially scrolling through infinite feeds governed by algorithms we do not understand with incentives that may not align with ours, as the "scrolling problem." This is not to be confused with scrolling through a single piece of writing, like an article or blog post. A lot of data are presented to us as infinite feeds, and in order to "stay updated" we have no choice but to scroll through it. This leads us to be reactive if the content has a clickbait element to it (flashy, outrage-inducing). This leads us to be quickly overwhelmed as the feeds force us to rapidly engage in task switching or simply pay a psychological price due to the negative stimuli in our feeds, both of which can lead to decreased cognitive performance.
The scrolling problem is a wicked problem: it is not particularly well-defined, but you know it when you see it. My strategy for solving a wicked problem is to solve a simpler but related problem, so I could get some momentum going. In my case, I have looked at avoidance and content curation as solutions where we can leverage pre-existing tools. In terms of tools that don't exist yet, I figured out how to view content as a map of topics rather than a feed, given the user additional control over what "regions" of a given feed they would like to look at.
Why the scrolling problem matters
First question: is the scrolling problem really a societal problem affecting a large fraction of internet users? Or is it just specific to me and/or you? One can answer that by doing a quick Google search of the term "stop scrolling." If you want a more scientific bent to the scrolling problem, type "stop scrolling" into PubMed. And scroll scroll scroll through the results…
I first started really thinking of the scrolling problem after I watched The Social Dilemma in 2020, which details the harmful ways social media has affected humanity at large. Hypernormal stimuli and inflammatory content is fed to us, and we consume the next item and the next item through feeds. It is a reactive process rather than a proactive process. We scroll through these feeds at the mercy of what comes next. Below, I talk specifically about context switching and exposure to negative content.
Context switching and productivity
I had an ADD diagnosis when I was a kid. My mom refused to put me on Ritalin, which was the first line of treatment at the time. I think it was one of the best decisions my mom ever made regarding my upbringing, as difficult as it was at the time. Without any meds, I had to figure out how to stay focused and productive in my own way. As a result, I like to think that now I became hypersensitive to things that de-rail focus and productivity, something I needed to get me through to the end of grad school. If this is true, then I have identified endless scrolling as one of them.
One of the issues that make up the scrolling problem is context switching. If we take social media as an example, you scroll through countless posts, each of which attempting to get you to click on something or react or comment in some way. Each post is not (so far as I know) grouped in relation to other posts. You could get a funny meme followed by a politically charged news article, followed by another unrealted funny meme. This is also known as context swtiching. The opposite of this type of stimuli might be deeply focusing on one subject for a long time. Cal Newport talks about this in his great book Deep Work, where he focuses on how to minimize context switching. There has been a lot of work on the detrimental effects of context switching, in terms of multitasking. Among other things, it leads to decreased academic performance especially facebook and text messaging, increased psychological stress including anxiety and depression, and decreased awareness of one's own performance in a given task.
Now, these papers focus a lot on social media, texting, and email burden, so it is not exactly the same as the simple act of scrolling through a feed for some period of time and assessing psychological state or performance in a task afterwords. Furthermore, some people like me scroll passively while others readily interact what what comes next. These could have very different psychological effects. Rather than making any sweeping statements at this time, I am going to simply make the hypothesis that if there is less context switching in my life, through less scrolling, then I will be more productive, more focused, and less stressed. The "ADD kid" in me will be kept at bay.
Now all this being said, passive or active scrolling will lead to exposure to negative and inflammatory content. You don't know what is going to come up next in your feed. We all know this from experience. This can indeed have a detremental effect on one's psychological state. It turns out that there is a word for both negative stimuli-laden scrolling and a word for the resulting psychological state.
Doomscrolling and mean world syndrome
In my research into the scrolling problem, I came across the highly relevant term doomscrolling. This is scrolling particularly through outrage-inducing content, leading one to fall into an increasingly bad mood, in which perhaps it feels like society faces impending doom. The wikipedia article I linked is very interesting, in that it puts into words a lot of issues that I have come across when I doomscroll. The first is mean world syndrome. This is a cognitive bias that arises from activities like doomscrolling can lead one to perceive the world as more dangerous than it actually is. One can see the gap between perceived danger and actual danger simply by looking at historical data. Steven Pinker does this in his book Better Angels of our Nature, which allowed me to clearly see how I was falling into the "mean world syndrome" camp.
We can't talk about mean world syndrome without talking more broadly about negative bias. This is the bias we enocounter when we're reading comments to our social media posts. One negative comment can derail us, offsetting 100 positive comments. This negative bias specifically says that negative stimuli have a greater effect than positive stimuli on psychological state. This isn't necessarily tied to memory formation (see the Polyanna Principle). For now, we will focus on psychological state. Part of the scrolling problem is that the act of scrolling, and especially doomscrolling has a detrimental effect on psychological state. The negative bias suggests that it would not take much negative stimuli in one's feeds to lead to a negative psychological state, something that should really be addressed for the sake of one's mental health. The scrolling problem is, at least in part, a mental health problem.
Solution 1: Restriction
“And if you don’t even take the things which are set before you, but are able even to reject them, then you will not only be a partner at the feasts of the gods, but also of their empire.”
— Epictetus, The Enchiridion
Given that doomscrolling has been defined and is part of the current discussion, meaning that at least that part of the scrolling problem is being addressed, what are the current solutions ot the scrolling problem? One way is avoidance. Limited news and social media. Tim Ferriss coined the term The Low Information Diet in his classic The 4 Hour Workweek. When I first learned about this concept, I brushed it off as absolutely preposterous. I was just out of undergrad and had a bit of a chip on my shoulder. "The internet is the future. Knowing everything is our moral duty. If I know exactly what is going on everywhere all the time, I will be a better person and make better decisions."
Maybe that would be the case in a world where news was properly curated and served to us in a more controlled and unbiased manner (which is something I'm trying to take a stab at with this project), but if we fast forward to 2022, news has been optimized to maximize for clicks over information content. This means that outrage-inducing stimuli is fair game if you are only optimizing for clicks and you don't care about other things, like the collective psychological state of people who have keys to the nuclear arsenal and people who vote them into office.
Furthermore, even before internet news and the incentive structure around it, there was enough negative news in the newspaper growing up to give me the idea that the news itself is overwhelmingly negative (which could possibly be my negative bias and mean world syndrome). You don't hear the news about all the people who had a perfectly average or even above average day. One exception to any negative bent on the news is a sub-reddit called Uplifting News, which literally finds and tells positive and feel-good current events. I'll talk about this kind of thing in our next section: curating your feeds so you get the inputs you want to see.
So then what are some good ways to practice avoidance of scrolling, and the low information diet?
Method 1: set designated times for scrolling
This involves blocking out timeframes where scrolling is allowed. This might be a specific time or set of times every day, or only on specific days of the week. For me, I try not to engage in any scrolling before my lunch break, and ideally not until the evening after I'm done working. What I find is that when I successfully abstain from scrolling until the evening, it is easier for me to simply not so any of it at all. It's similar to my (limited) experience with fasting, where at first you're very hungry, but then at some point the hunger pains go away.
When it comes time to scroll, what I try to do is block out a specific and short time window. 15 minutes, or whatever works for you. If I'm in a phase of my life where I'm actively posting to social media, what I try to do is log on with a specific objective in mind. I am only going to respond to comments on my post. If I don't do this, then I find myself mindlessly scrolling.
Method 2: use tools that limit your scrolling time
There are various browser tools that help you from getting distracted. In grad school, I used a browser extension called StayFocused. How it worked, and how I'm guessing others work, is you list a set of websites that you absolutely do not want to visit during a designated time frame for designated days, that you also set. For me, it was news and social media, Monday-Friday 9am-6pm. How it worked was that between those hours, I had a total allotted time of 10 minutes with which I could do whatever I want on any of those sites. Every time I visited a site on the list, the timer would start ticking. The timer would stop ticking when I went to a site not on the list. This kind of thing can backfire, though. During my more vulnerable moments, when for example I was very sleep deprived, I found myself going into other browsers when the time ran out. So be careful. Your mind will figure out ways around it.
Another trick I use is on my phone. I take all the news, social media, and scroll-centric apps and I place them into a folder labeled "distractions." This gives me a little bit of a buffer, because every time I find myself going to one of those apps, I have to acknowledge that I am entering the distractions folder and therefore am distracted. If I really pay attention to my mannerisms, I realize that a handful of my moments where I pick up the phone and start scrolling are unconscious. It is the word "distractions" that allows me to snap back into focus and say "oh, I'm doing that thing that I'm really trying not to do."
There's another useful trick that I use mainly when I'm on my computer. When I enter an infinite-scrolling environment, like Twitter, I wait a few seconds to let everything load, and then I shut off the internet connection (for me, it's Wi-Fi). If you do it like this, then the feed cannot re-load by definition. For Twitter, a lot of short videos farther down in the feed won't properly load without internet connection. As such, what I do is I turn off the wifi, scroll down to the bottom of the feed, turn the internet connection back on, and scroll upward to the top. When I get to the top, I consider my designated scrolling time to be done and I log out. You can do this for the phone as well, but you have to open an app (for me, it's usually Instagram), then turn off both the Wi-Fi and cellular data, then go back into the app.
Here are some examples of pre-existing tools that you can use to keep the scrolling at bay. This list is nowhere near exhaustive, but it is meant to give you an idea of the types of tools that already exist that you can start using today.
Distract Me Not: a Firefox add-on that blocks websites that you list, with day and time specifications possible. Similar to the one I've used.
DF YouTube: a Firefox extension for YouTube that removes the feeds and disables autoplay. It essentially removes the scrolling problem from YouTube.
Grayscale Bro: a Firefox extension that removes color from everything you're looking at. Shades of gray blunt a lot of the hypernormal stimuli that would otherwise get you to click on something on impulse.
Textise-It: A Firefox extension that allows for the viewing of websites in text-only mode. This means that no pictures are uploaded. This has helped me with respect to viewing news and social media, as it keeps me from being biased from any images associated with articles and posts.
Text-only browsers: Related to Textise-It, there is a whole class of text only web browsers. From this list, I use Emacs/EWW.
Method 3: mindfulness of the urge to scroll
This is something that I have been doing lately, and this is the method that I think will benefit you most in the long term, not just with respect to the scrolling problem. Mindfulness is a type of meditation where you simply focus your attention on either particular aspects of experience (like where you feel your breath, or the feeling of the air on the back of your hands), or experience as a whole. Its very curiosity driven. What does experience really feel like? Where do thoughts and feelings come from, how long do they stick around, and where do they go? There are plenty of guided mindfulness meditation apps out there. The one I'm currently using is Waking Up, from neuroscientist and philosopher Sam Harris. If you want a scientific primer for what mindfulness is, what the benefits are, and how to do it, please listen to his appearance on the Huberman Lab podcast.
What does this have to do with the scrolling problem? Well, upon doing mindfulness for a while, I became aware of how I felt moments before succumbing to a craving. Next time you're reaching for that piece of candy or handful of potato chips, try and locate the exact feeling you have the moment before your hand starts to move. If you can sit with that for a few seconds and recognize that it's merely a feeling that comes and goes, you're already well on your way to stopping the loop.
My phone is on my nightstand. If I get up in the morning and I posted something to social media the evening before or something like that, I have a strong urge to reach for my phone, hop on LinkedIn or wherever, look at the feedback, and then scroll to the next post, and the next one. Not a good way to start your morning. So what I was able to do after a bit of mindfulness practice was locate the exact feeling I get just as my hand is about to move to grab my phone and assume the scrolling position. It's the feeling of my brain craving a quick hit of dopamine (well…its more complicated than that, but this is the modern parlance). For me, it's comparable to reaching for that next handful of potato chips, but without the mouth watering. The point is I'm familiar with how that feels, and I can sit with that feeling without acting on it because I know that the feeling will come and go pretty quickly, and I know it down to the exact intensity and kinetics.
There's that old saying "curiosity killed the cat" (and I'm not going to speculate about the origin here). In the case of mindfulness applied to the scrolling problem, curiosity killed the craving.
Solution 2: Curation
“Garbage in, garbage out. Or rather more felicitously: the tree of nonsense is watered with error, and from its branches swing the pumpkins of disaster.”
— Nick Harkaway, The Gone-Away World
There are plenty of sub-regions of the internet and social media that might be relevant to your goals, your career, your relationships, and so on. As such, for many people, it is not realistic to completely abstain from scrolling through feeds. For example, I try not to spend too much time on Twitter, but when new developments in AI happen that are relevant to my work, Twitter is the place where productive discussions at the leading edge are taking place. So I have to go on Twitter with a very narrow focus on learning something new about some new development in AI, and try not to get sucked into any of the other drama that I will naturally run into by the simple act of scrolling.
Method 1: programmatic access to social media.
If we stick with Twitter for a moment, you can programatically access Twitter via its own API, or even with web scrapers. I have scripts that pull tweets from relevant users into tables that I view either in excel or via html. This allows me to get what I need from Twitter without being at the hands of its algorithm. One example of this is my preprint history archive that I maintain. The preprint servers Biorxiv and Medrxiv automatically post to Twitter the instant a pre-print is uploaded. The tweet includes the title and a link. I pull these and the metadata (eg. likes, retweets) into a table so you can ask simple questions about what the most popular pre-prints within a particular timeframe pertaining to a particular subject were, in whatever order you'd like to see them. But you can extend this concept to any user or users, essentially creating your own "feed" without encountering the scrolling problem.
Method 2: RSS feeds
RSS feeds are something that I'm only recently getting into. They used to be a common way of curating information on the internet relevant to you, but this has largely been replaced by social media. And RSS feed is a particular web format standard that would allow you to subscribe to specific websites, like blogs, or news sites. What you do on your end is get a RSS feed reader, which takes the RSS based content of the websites you're interested in and gives it to you as a list of content you can go through. It feels less like scrolling and more like checking your emails.
RSS feeds removes the algorithm-driven infinite scroll feature of the main social media platforms, prevents any recommended content or ads from showing up, and gives you more control over what you see. Of note: Google killed its RSS feed reader (called Google Reader) in 2013, suggesting that RSS is not exactly as popular as it used to be. But perhaps RSS feeds is a healthier way of getting information from the internet. You still wouldn't have control over whether a given news site would serve up something inflammatory that ruins your mood, but you would be able to easily unsubscribe to anything you don't like, and not worry about some algorithm serving up recommended content from feeds you're not subscribed to.
Some RSS feed readers you can try:
Feedly: an Android based RSS feed reader that has over 5M downloads.
Newsblur: an RSS feed reader for both Android and iOS that has many different interesting features. It can also get feeds from websites like Twitter and YouTube that don't have RSS.
Elfeed: for Emacs users. This is the one I use. From the developer: "As far as I know, outside of Elfeed there does not exist an extensible, text-file configured, power-user web feed client that can handle a reasonable number of feeds. The existing clients I've tried are missing some important capability that limits its usefulness to me."
Solution 3: Maps
"I was a few miles south of Louisville when I planned my journey. I spread out my map under a tree and made up my mind to go through Kentucky, Tennessee, and Georgia to Florida, thence to Cuba, thence to some part of South America; but it will be only a hasty walk. I am thankful, however, for so much."
— John Muir, A Thousand-Mile Walk to the Gulf
Motivation for maps, where my work begins
My work on the scrolling problem aims to give the user a bit more control over the act of scrolling itself. The idea is we can't eliminate scrolling entirely. We have to know at least a little bit of what is going on in the world, so we don't get shell shocked when we get to the store and there is no toilet paper or hand sanitizer on the shelves. Furthermore, even if we inundate our feeds with positive content, we still have little control over what the next item is going to be as we scroll. Every once in a while, something gets through. There was a time a few years ago where my Facebook feed filled up with heartbreaking stories of animals in shelters who had been abused, sometimes with graphic pictures. I can't tell you if this is a trend that everyone saw, or if a handful of my Facebook friends were sharing things like this. The point is, if you scroll long enough, you're going to get hit by something that drags down your mood, and perhaps with it your cognitive performance and productivity, for the rest of the day.
This is one reason I am focused on turning my feeds into maps. If sensitive political content is peppering the news and you don't want it to distract you from an important deadline coming up, then you just avoid that part of the news map, and check the rest of the news. If you only want to read about tennis and not get distracted by football, then just zoom into the tennis subsection of the sports section of the map. If you are in the mood to be outraged by the social and political ideologies you disagree with, then there is a section of the map for you too.
From feeds to maps
Here is what viewing your feed as a map would ideally like: rather than having an endless list of tweets, posts, news articles, search results, emails, TODOs, and things of that nature, you have a map. Passages that are similar to each other are near each other based on context. A tweet about dogs and another tweet about dogs would be near each other. A tweet about cats would be near the tweets about dogs because they are related in the context of "pets."
Focusing on social media, imagine your entire twitter feed is a map. You now have more control. Different regions of the map would be about various topics, from celebrity gossip to sports to social justice. You would have control over where in your "feed" you want to go. You could be able to avoid outrage-inducing content if that's what you wish. You could focus on a particular set of topics in your feed so you don't get "sucked in."
Now imagine you're searching PubMed for every scientific paper for a particular disease you're interested in. There could be thousands of papers. Now let's say your results are a map. AI-based papers are to the northeast. Clinical trial papers are to the south. And so on, with each region of the map properly labeled. These broad searches are a good use case for the map view.
My text-to-map protocol
The tools needed to convert text to maps are open source and readily avilable if you know how to code. My protocol revolves around the use of the BERT language model (there are alternatives, but this one works well enough and is open source). BERT is a pre-trained transformer that takes any text up to 512 words long and converts it into a 768 element vector. Broadly speaking, you can think of this high-dimensional "context space." Data scientists are used to operating with high-dimensional data like this. We know how to program computers to understand this type of data. However, for it to be human readable, we have to somehow turn these 768 dimensional coordinates into a simple XY plane that we're used to.
That's where UMAP comes in. It is a non-linear dimension reduction algorithm. It takes each 768 dimensional vector and converts it into a 2 dimensional vector. Vectors (texts) that are similar to each other in the 768 dimensional space will be near each other in 2 dimensions. In other words, you end up with a map, where each point on the map is a text you care about. A text that would otherwise show up as part of your endless scrolling ritual. Now you have a bit more control, as your feed is now a map. UMAP is by no means perfect. You can't perfectly compress 768 dimensions without losing information, but you'll be able to see in later sections that it is good enough to be useful in our goal of solving the scrolling problem.
There are other technicalities for the interested user (warning: jargon coming). One can do a preliminary step of determining the effective dimensionality of the data by determining how many principal components explain 95% of the variance. In my experience so far, it's roughly 1/3 of the total dimensions. This could increase both speed and accurracy given you're operating with more signal and less noise.
Additional steps are standard in unsupervised learning and useful here. Clustering the data, so we can access it at the group level is convenient here. Extracting keywords from each cluster helps us determine what clusters are the "sports" versus the "politics that will make me upset" clusters. All of this gets visualized on the map.
The map must be interactive and clickable. I'll get into this later, but I'm using the plotly package to produce such maps. The best practices (in my domain) for clickable "maps" come from flow cytometry analysis, which involve drawing "gates" around populations of interest. Flow cytometry users will most definitely find the "map" solution to the scrolling problem to be intuitive.
A context map view of the news
The news is a high-impact low hanging fruit for this type of analysis. I am often bombarded by too much information, as well as hypernormal clickbait. I decided to make a map based on the news article titles to create a "neterws space" that I could query from the map view. The easiest solution to doing this was to use twitter. The major news outlets have twitter accounts. These accounts tweet out articles as they come in, as part of the 24 hour news cycle. The text of the tweets is typically the title of the article in question, followed by a hyperlink. This means that I can get the text of the title of the article without having to click on the hyperlink. I just need the tweet itself. Thus, I can create a news map by means of collecting tweets and using the text as input. I collected twitter handles for the major news outlets, from AP to CNBC. I used the twitter API to collect as many tweets from each handle as I possibly could, in order to create a more nuanced "news space."
In researching what has been done to solve the scrolling problem with respect to the news, I found a handful of sites that take news articles and literally place them onto a world map. At the time of writing this sentence google has a Google News to Google Maps connection here that achieves this aim. I like this because it allows the user to organize the news in terms of regions. Another one that is quite a bit more in-depth is this interactive map of the world news, by the Gdelt Project, a beautiful undertaking to monitor everything that is taking place everywhere in the world, at the map level. It is a bit overwhelming (which is one of the issues with scrolling I'm trying to solve), but the user nonetheless gets control over which regions will be the area of focus for a given news search. Furthermore, it allows the user to (ideally) see how much of the news is concentrated in a particular country. For example, if there is an election in a particular country, there will be a significant increase in news focus on that particular country.
What I am doing is similar in that the output is a map. However, it is different in that I'm using an abstract "similarity space" rather than a literal map. The benefit there is that articles about inflation will be mapped to a particular region. Articles about how inflation is affecting the price of Bitcoin will me adjacent to that. Articles about Bitcoin in general will be adjacent to that. Articles about Cryptocurrencies including but not limited to Bitcoin will be adjacent to that. So it is a map of how current events are related to each other in context rather than where they are located. I like to think of it in terms of how a conversation would go. Inflation -> Speaking of which…Bitcoin -> Speaking of which…Crypto.
Let's dig into the web app. We'll go through various news sources, starting with AP, which I chose for broad, relatively unbiased reporting.
AP
Below we have a screen with the map in its current form.
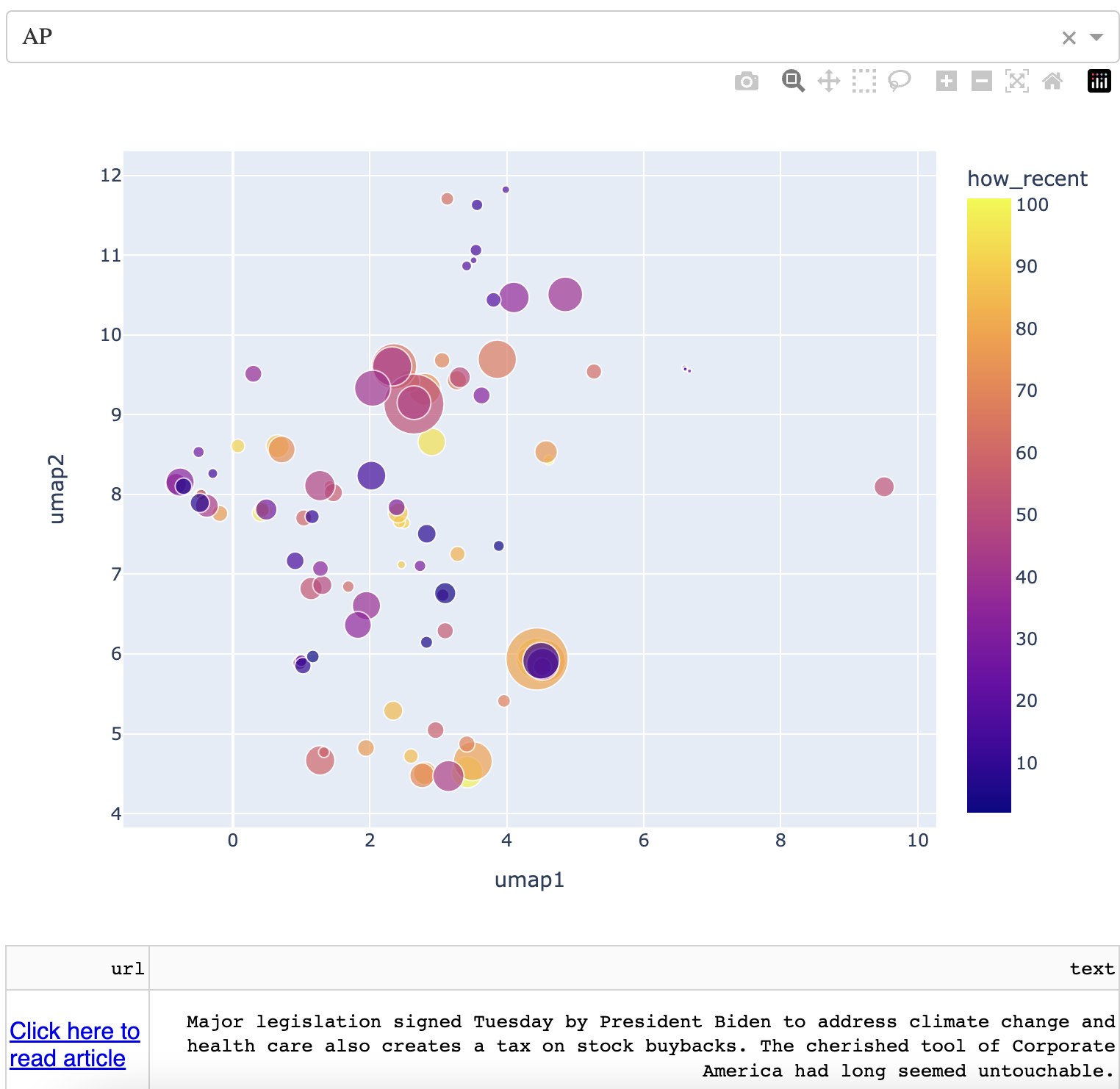
Note that there is a dropdown menu on the top, that displays various news sources. The map is below that. There are two boxes below the map, with the right side containing an article title and the left side containing the corresponding hyperlink to the article.
On the map, each point is a news article from the twitter feed of the news source in the dropdown. The size of the article corresponds to the number of likes relative to the rest of the points on the map. The color corresponds to how new the article is, with yellow being the most recent.
On the desktop version, the user can hover onto each point and get information about it. On mobile or iPad, the user taps on each point to get the same information. The information is below.
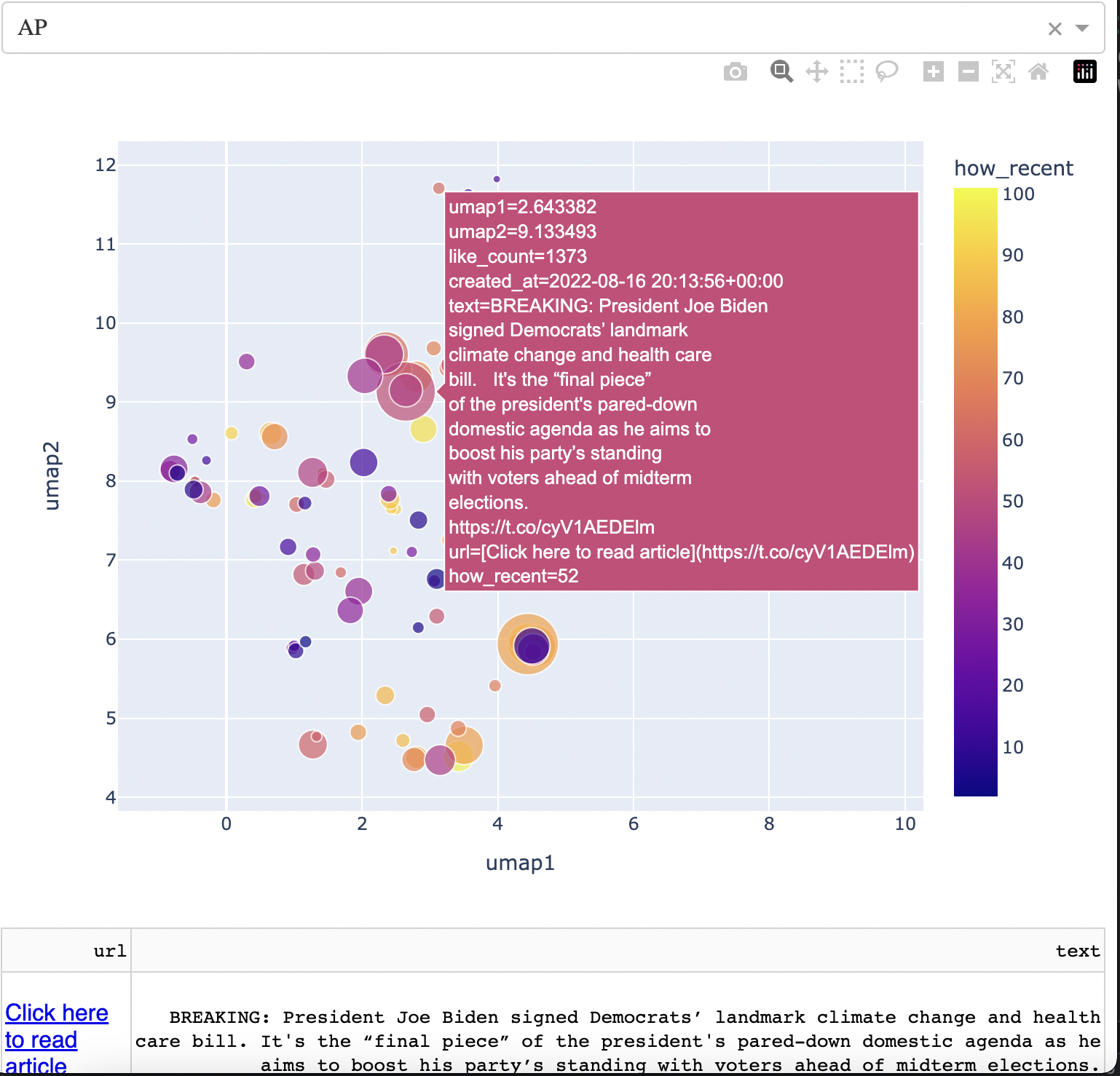
You can see that you can view various things, from the text of the article to likes and retweets.
Importantly, similar news articles are grouped near each other in terms of context. The news article above is in a "Biden" cluster. One way to quickly gain some intuition around how the articles are grouped is to simply go through the dropdown and look at other news sources.
ESPN
For example, contrast the layout of AP, which is relatively broad across the map, with that of ESPN.
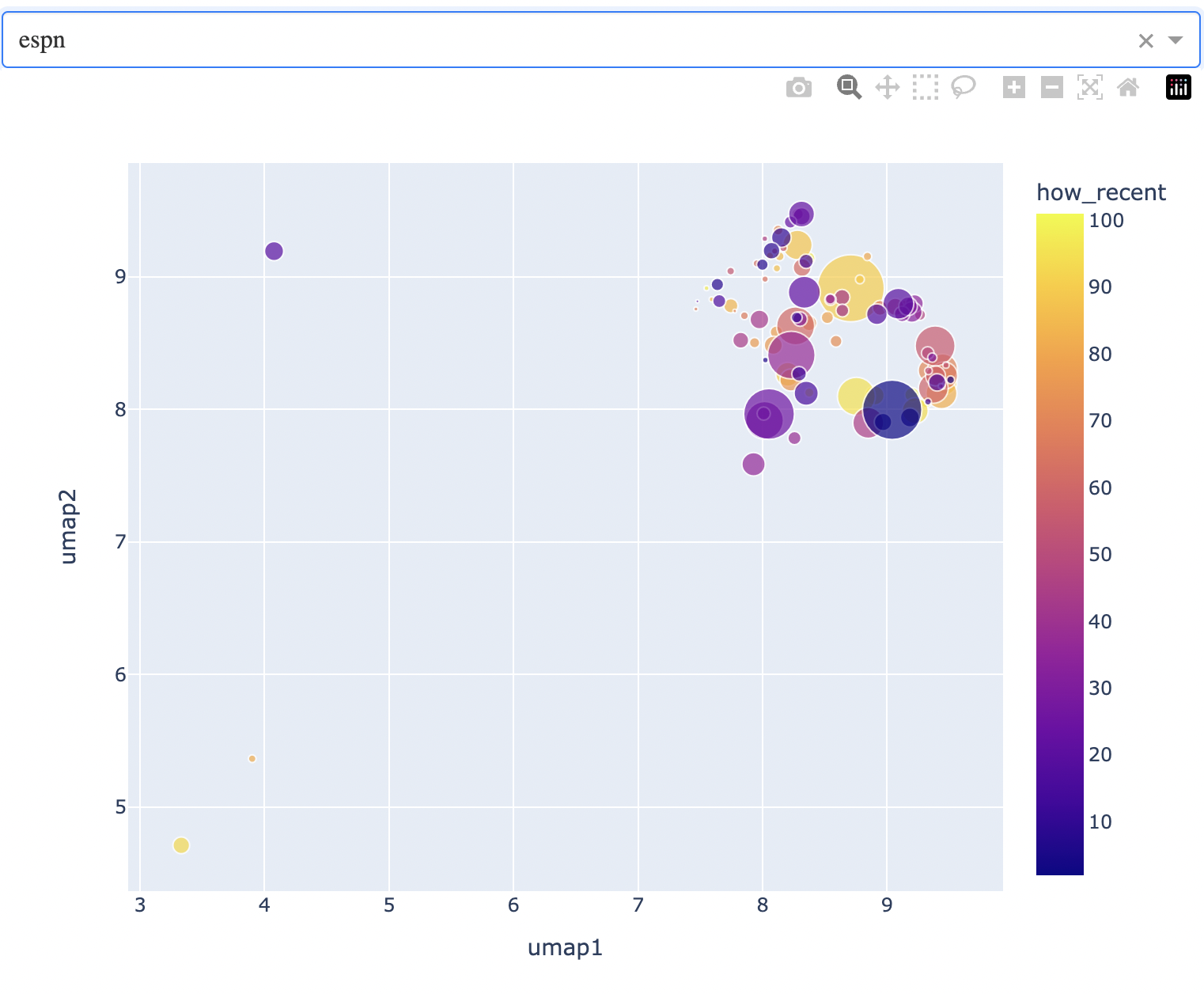
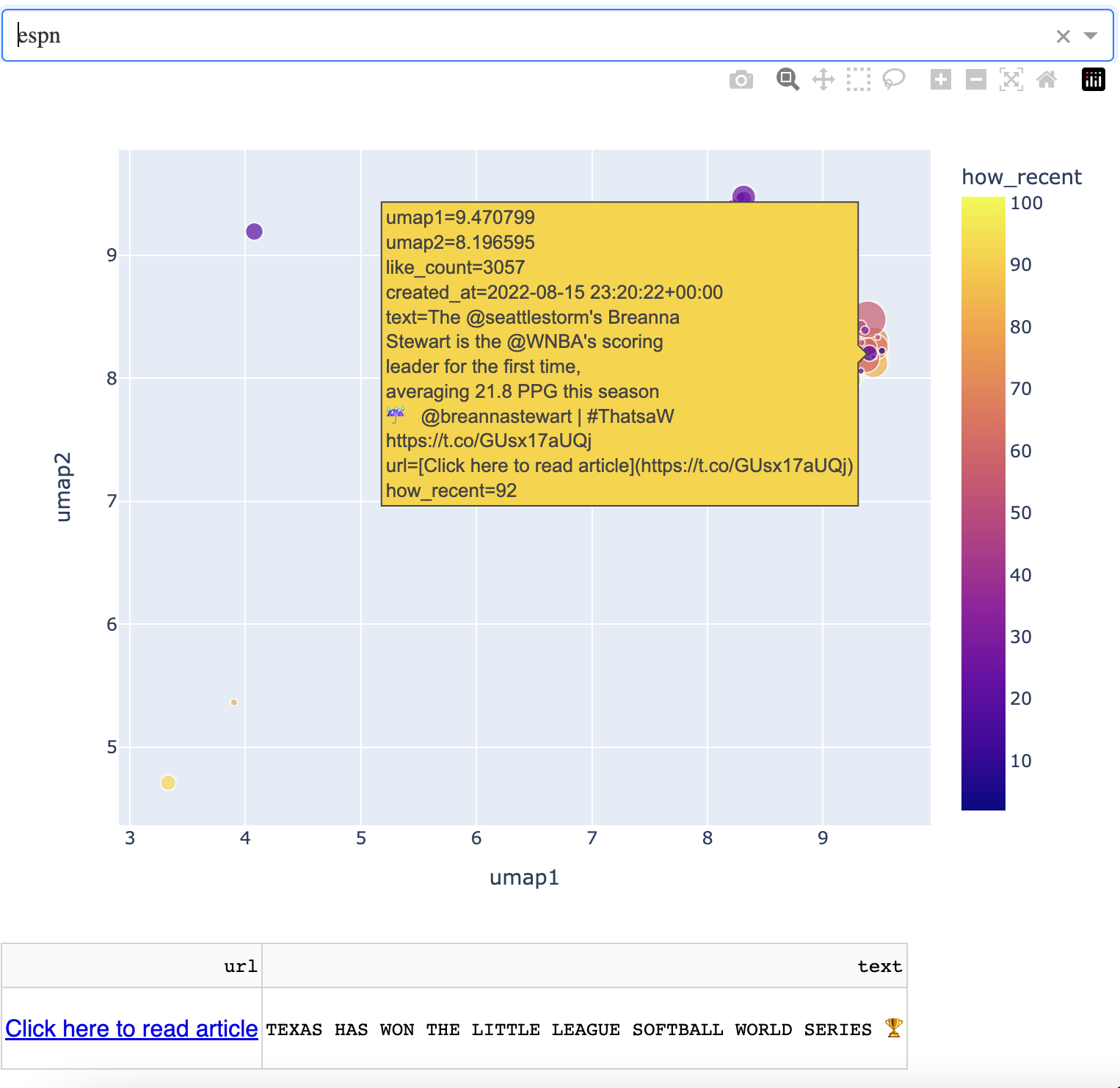
You can see that the ESPN news (sports) occupies the northeast corner of the map, and it is a much more focused region. In this current iteration for example, the northernmost articles are around the Little League World Series…
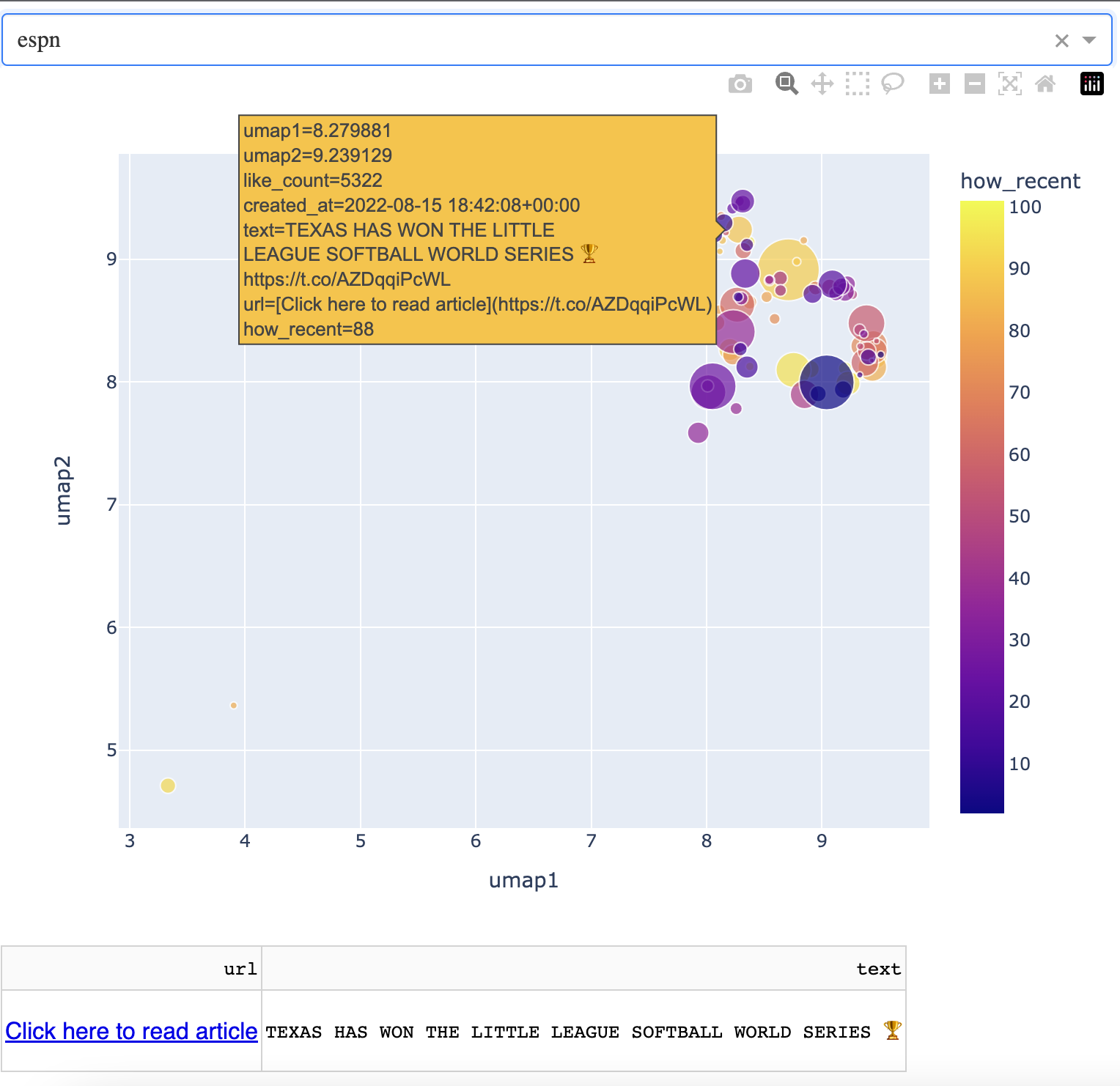
…and the easternmost articles are around the WNBA.
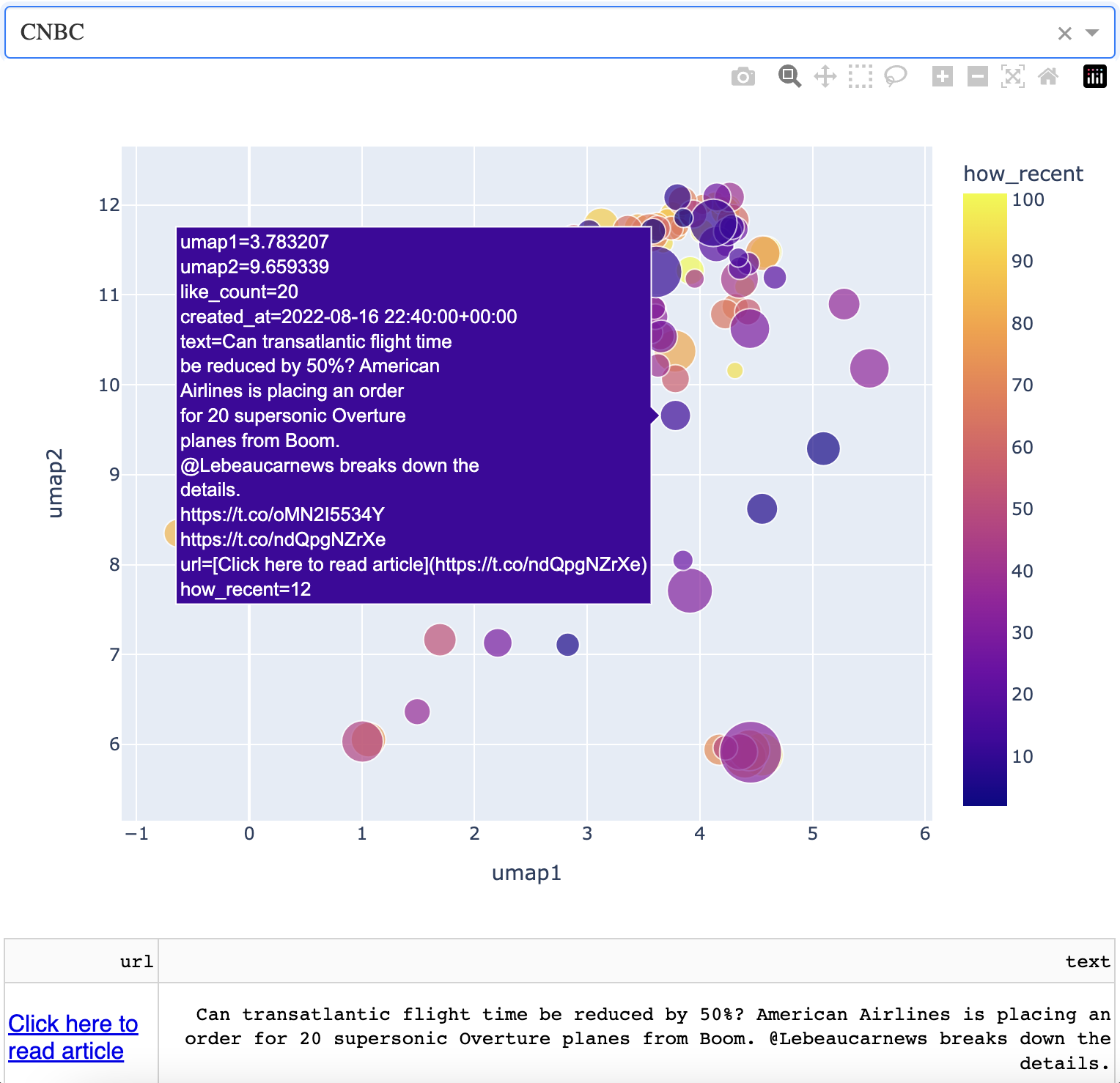
CNBC
Now if we switch gears and look at CNBC, we can get a feel for business and finance news.
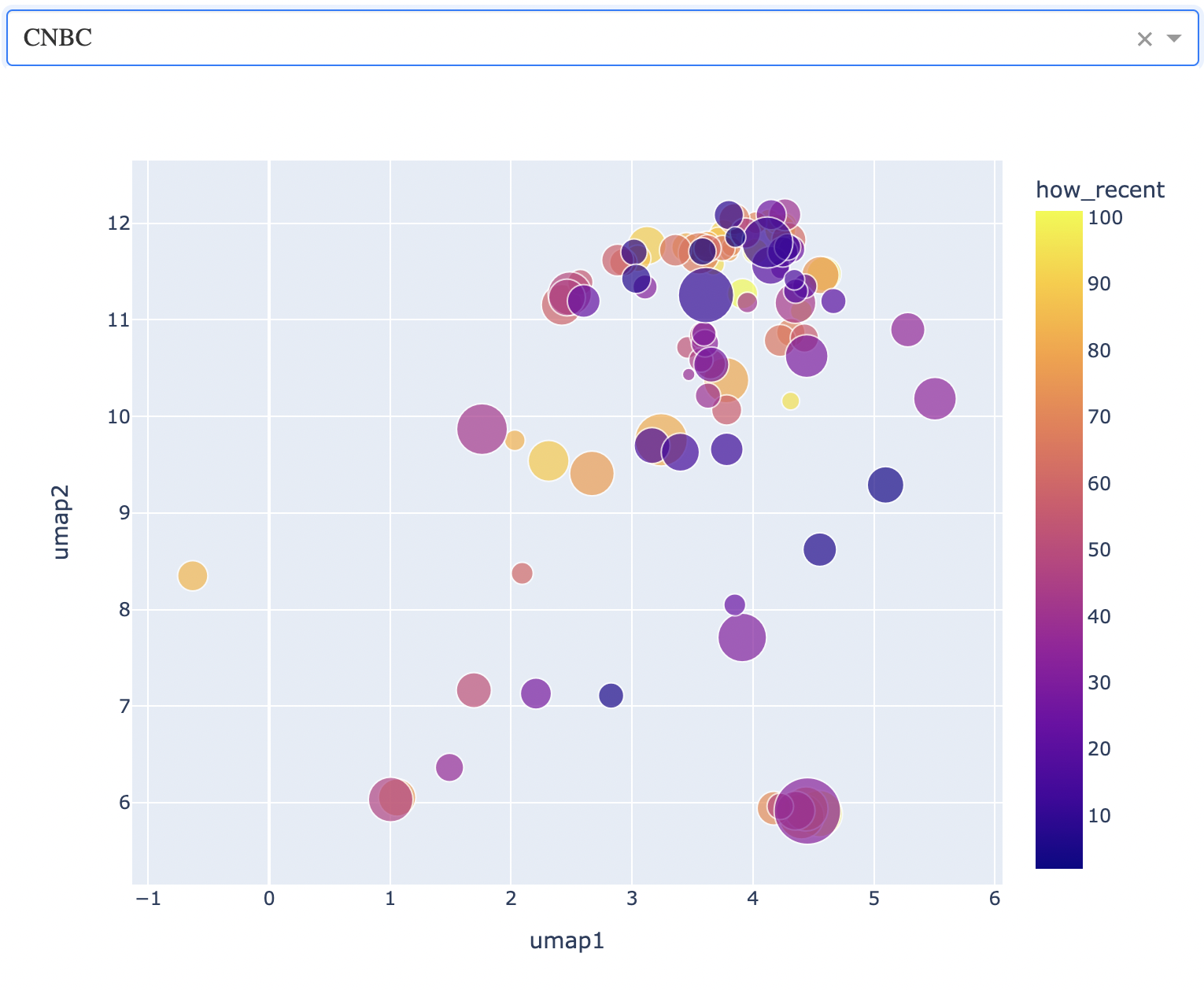
Here, you can see that the news articles are a bit more sparse on the map. The northernmost points correspond to how stocks are doing. Not too well at the time of writing. I note that American and European markets lump together in this region. Below is an example of a news article from here.
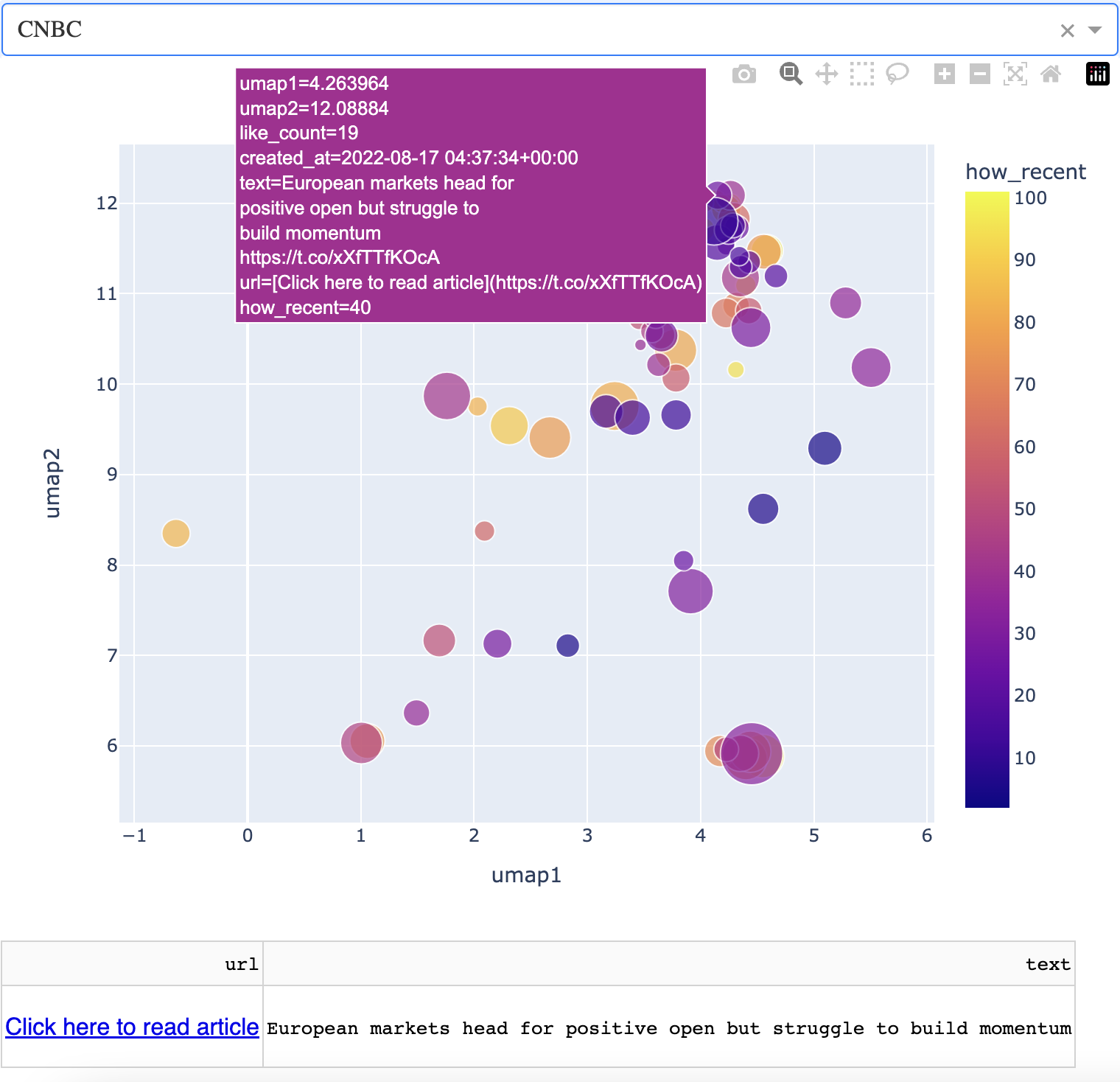
Follow this "line" of articles west and you'll get to a small island that corresponds to UK market information. When I went south, I found an interesting cluster of articles corresponding to Dodge intending to switch to electric. At the time of writing, many carmakers other than Tesla are beginning to make electric cars.
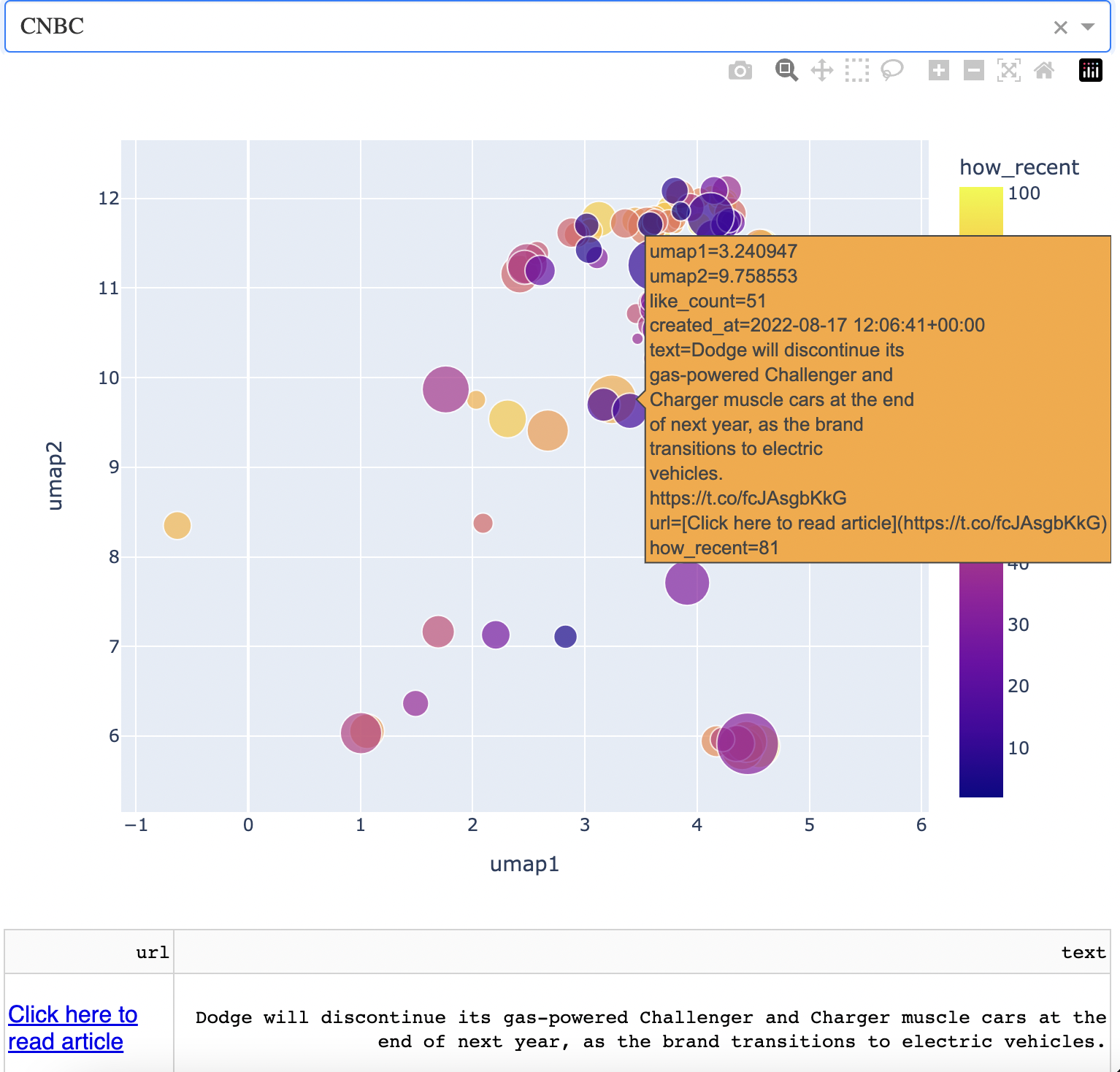
I thought I would see news about Elon Musk and Tesla nearby, but I didn't. Rather, I saw articles around air and rail travel. I found this to be a nice example of grouping by context, which the AI powering this map seems to be doing. One example is below.
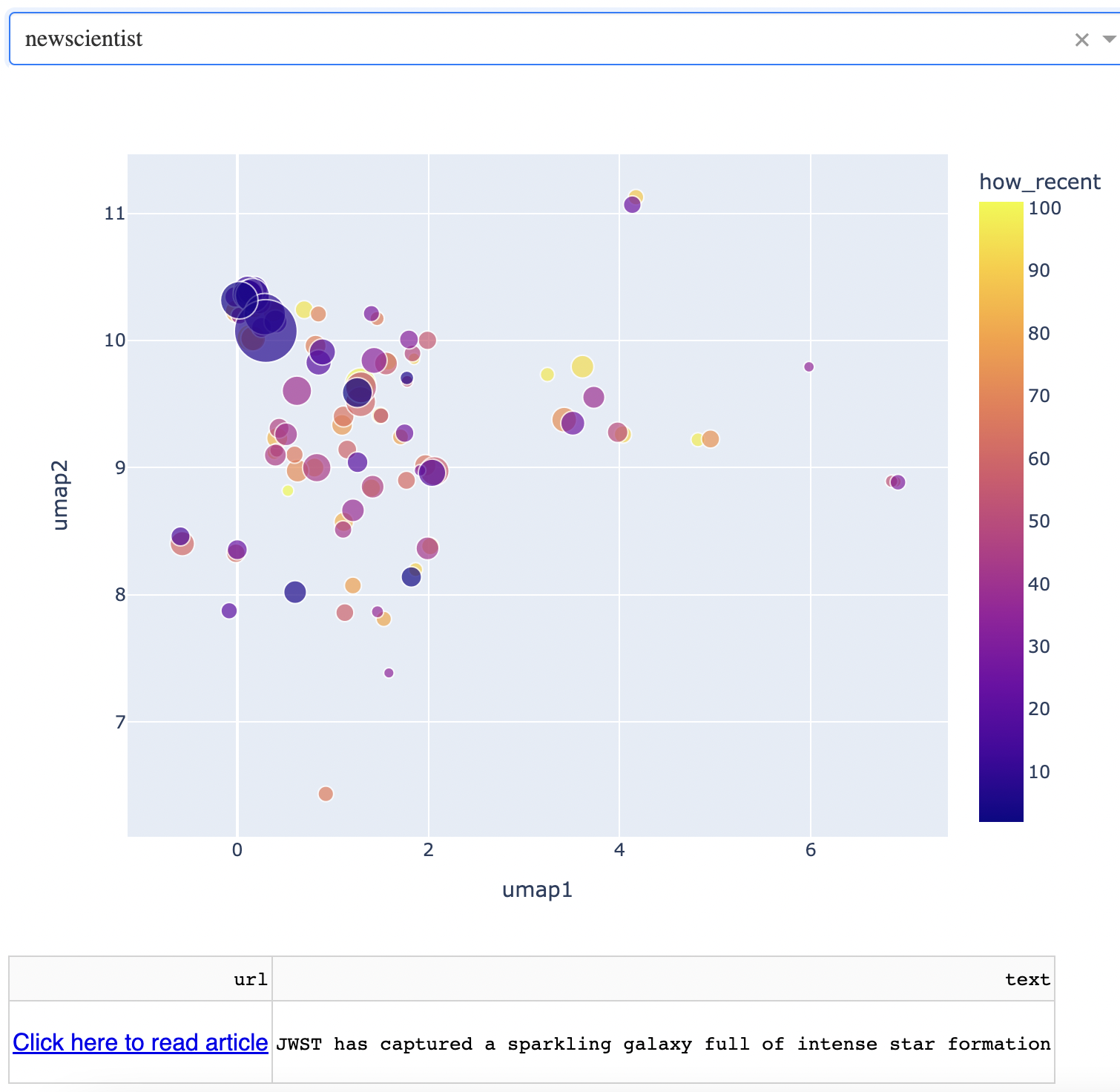
New Scientist
Finally, we will look at science news. This is from New Scientist, which is the most followed science news related twitter account at the time of writing. Below is a picture of the map. You can see that science covers the westrn half of the map. The very large points correspond to news about the James Webb Space Telescope, which was recently launched.
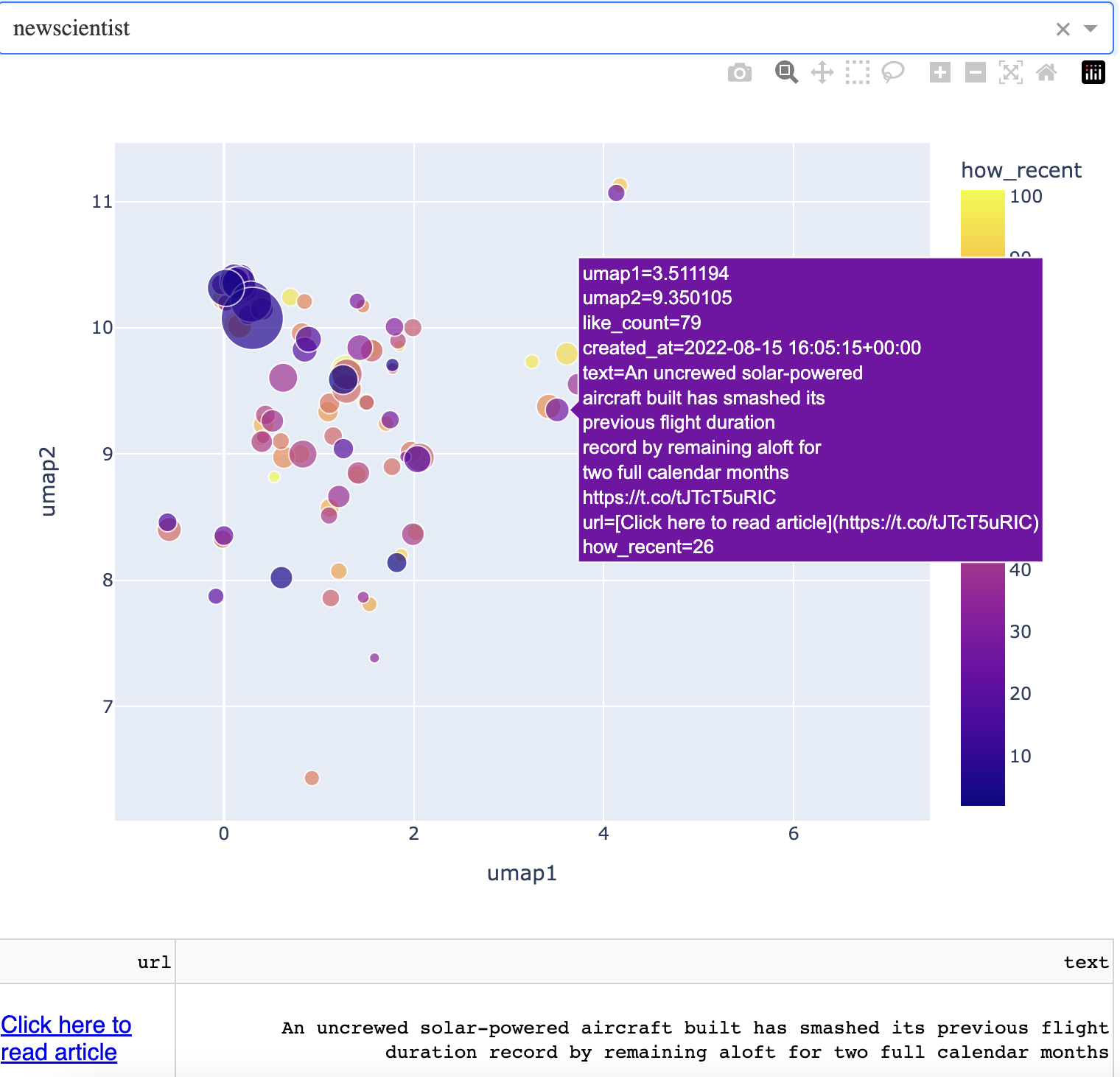
I'll focus for now on the small cluster of articles that is just east of the large cluster on the west side that makes up the bulk of articles. I found an interesting aspect of how the algorithm works here. Below is an article on flight duration.
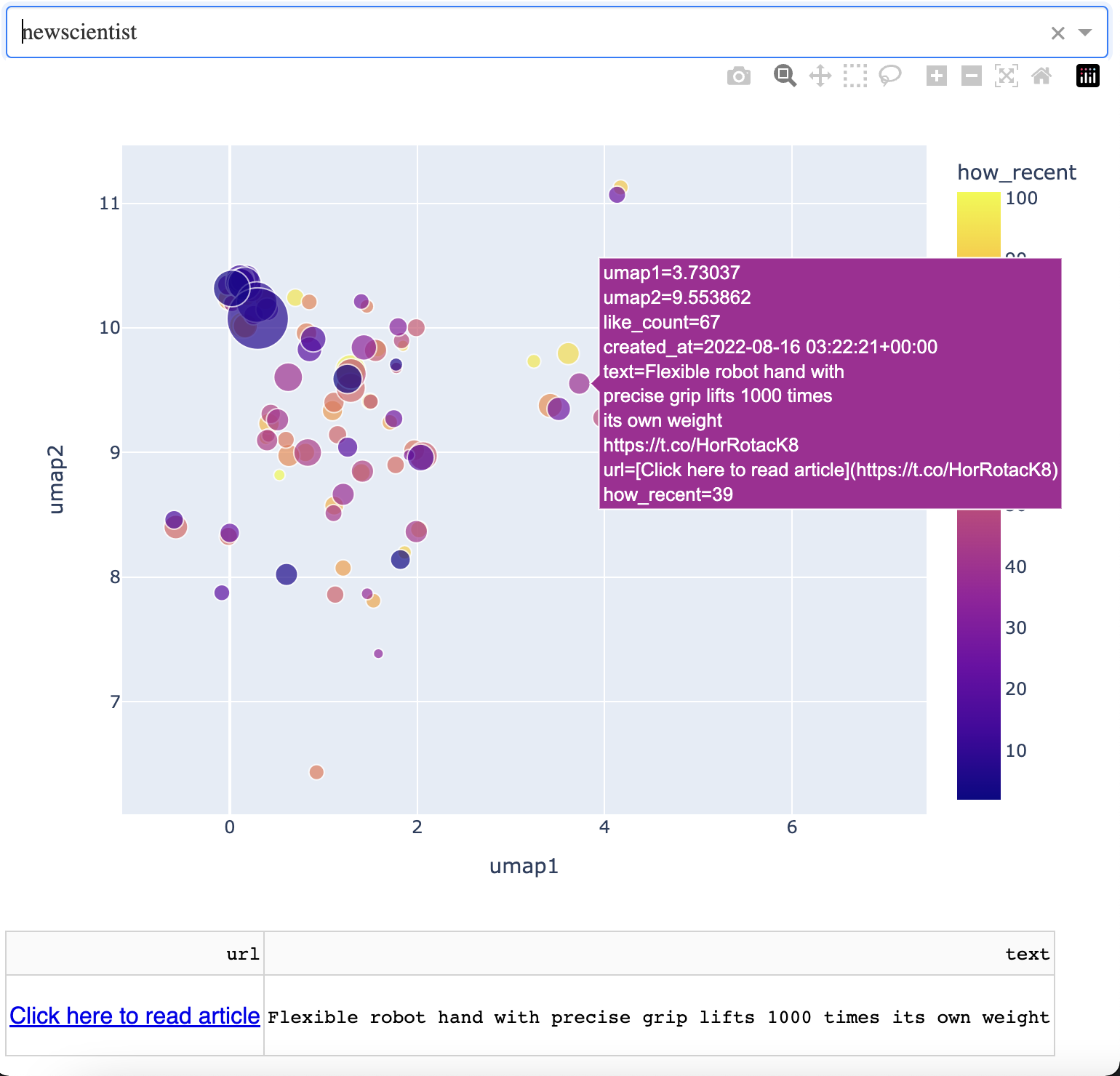
Next door to that is an article about the strength of a robot hand.
So far, we're looking at performance of technology. But here is the twist. Below is an article about "why thinking hard for a long time can leave you exhausted."
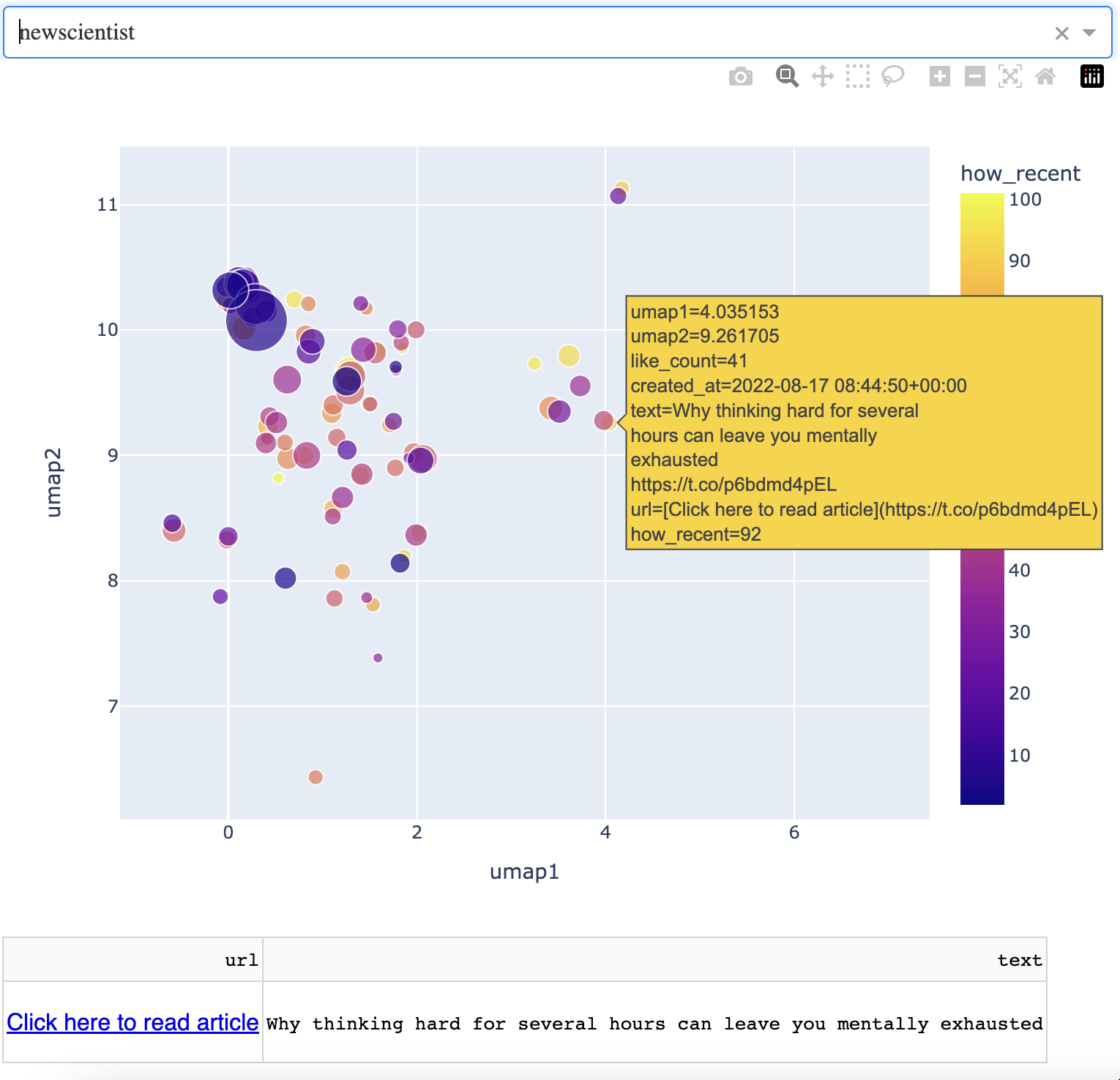
So you can see that we're dealing with a "general performance" cluster, that lumps human and machine together. This type of bottom-up discovery of what the AI is doing is both critical and entertaining, in terms of getting the most out of the app.
Additional optimizations
I am far from finished in terms of optimizing the map. Obvious functional things to be done include adding additional twitter handles into the dropdown at the top. Ideally, I'd want to simply have a blank text box where the user adds the twitter handle of interest to generate the map, so the user could get a map view of way more than just the news. The reason why I can't do that right now is because I'm using the twitter API, which only allows a limited number of tweets to be pulled per month. When I have a lot of different users pulling tweets all the time, I'll reach my monthly limit very fast. Another option that I might do is teach users how to create their own authorization codes for their own use of the twitter API. That could be a simple instructional page. But that will happen down the line.
Generalization of the map view solution
In terms of generalizing this map viewer, there are many additional use cases, ranging from competitive business intelligence to map-assisted Google searches. I'm currently working on many of these. I don't know if others are going to be interested in each of these use cases. At this point, I am merely scratching my own itch.
How I am using this web app in my everyday life
Every morning, I update the app to include new news articles. I do check the news outside of the web app, but only to check the headlines. For a deeper dive into the news, I use the app. I generate the maps and I go through each of the news sources in the dropdown to get intuition around where each news type is. I note that at the time of writing, the news gets mapped differently every time I bring in new articles. I'm currently working on this with a few friends, but it is technically challenging. I generally start wit AP and CNN Breaking News. I look at what is newest in relation to the rest of the map. I then go into CNBC and the rest of them depending on what I am looking for that day.
I am slowly getting feedback from others, and trying to emphasize form over function. I could spend hundreds of hours (or lots of money) making the site look sleek and professional. But it's going to give you the same information at the end of the day. If you have any feedback for me, don't hesitate to reach out.
Toward an anti-scrolling protocol
I get up in the morning and very quickly I feel the need to reach for my phone and see what's in the news, or social media, or whatever else. I take no action but simply remain mindful of the feeling of the need to hop on the phone and start scrolling. I watch as the feeling rises in intensity, peaks, and then passes. Doing this breaks its spell.
But I have to check the feeds at some point, right? So to get up to date with everything, I hop onto my RSS feed reader, which has updates from news, tweets, and blogs I follow. While there is some scrolling involved, this removes the "infinity" from the scrolling. Of note, I try to do this later in the day. I find that if I can spend the morning doing things I need to do without getting distracted by scrolling, it seems to help me gain some psychological momentum in the direction of focusing.
Even if we make our feeds finite, we still run into instances where a given feed is overwhelming. There are hundreds of new stories or tweets pertaining to a topic of interest. This often happens when I'm researching a broad topic and I don't know where to start. This is when I place a given feed into a topic map, which gives me an additional layer of control where I can determine what particular sub-topics I want to dive into, rather than scrolling my way into them (and getting distracted along the way).
There are days where I'm simply more susceptible to scrolling than others. This often happens when I lose sleep. For those days, I layer on the additional tools I talked about. I'll make my background black and white. I'll activate text-only mode on my browser. I'll set up blocks on particular sites that I know I'll get lost in.
I don't see this as a linear protocol as much as I see it as a menu of protocols to choose from depending on the individual circumstance. It's not perfect, but what has helped me is simply setting up protocols to address particular situations where I might get lost in an infinite feed. From there, I'm in an OODA loop (observe, orient, decide, act). I observe the compulsion to scroll, orient myself to the situation and context, decide upon what anti-scrolling protocol to enact, and act on the protocol.
Conclusions and future directions
I've defined the scrolling problem as the set of problems associated with scrolling through infinite feeds controlled by algorithms we do not understand that have incentives that may not align with our own. I initially defined the scrolling problem for myself because I saw scrolling was starting to affect my mental health and the mental health of my peers.
One solution I defined was avoidance. This was at least restricting your scrolling to designated days and times. I also showed how the use of pre-existing tools could help you restrict scrolling. These tools could work either through restricting your access to particular sites, or through displaying the web in text only mode, which would remove images and videos that would otherwise tempt you to scroll. Another solution I defined was content curation. This was either using programmatic access to content to create your own finite feeds, or using pre-existing RSS feeds and a feed reader to turn what is otherwise scrolling into what feels like checking email.
The third solution was the use of AI to turn a given feed into a topic map, giving the user control over what regions of the map they would like to visit. I spent some time explaining and showing the map solution to give the reader an idea of what exactly a topic map is like and just now news articles would be grouped in such a map format. I explain that this is a work in progress, but I'm already using it to great success for checking the news.
I'll end by saying that since I have been on this pursuit to solve the scrolling problem, my mental health and clarity of thinking have both improved. I attribute this both to less time spent scrolling and less stress from having more control over my information intake. I think what helps is being able to characterize the scrolling problem in your life. My guess is that the scrolling problem will be a little bit different for each person, based on their social media habits, information intake habits, work schedule, responsibilities, whether or not they're a content creator, and things of that nature. A problem well defined is half solved. If you can characterize the scrolling problem in your life to the best of your ability, then you'll have an idea of which of the solutions I've presented are most relevant to your situation. Overall, I hope my work helps you improve your mental health and clarity of thought as it did with me.